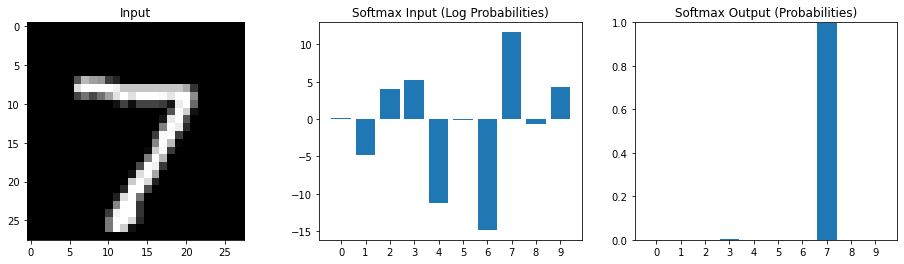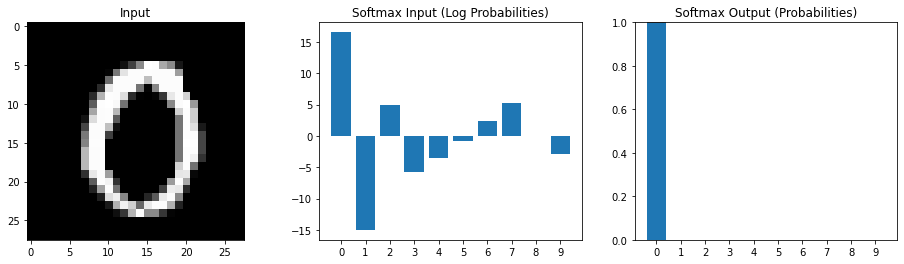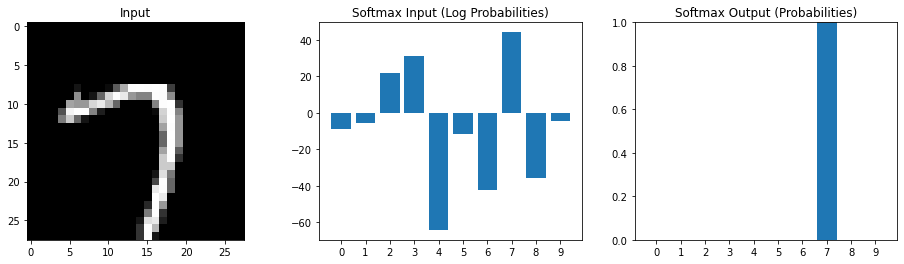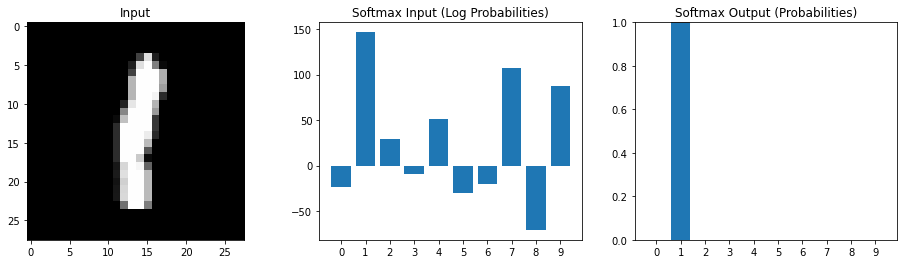
Device: cuda
.Epoch 0, train accuracy 0.431, test accuracy 0.650
.Epoch 1, train accuracy 0.737, test accuracy 0.792
.Epoch 2, train accuracy 0.829, test accuracy 0.843
.Epoch 3, train accuracy 0.876, test accuracy 0.884
.Epoch 4, train accuracy 0.896, test accuracy 0.904
.Epoch 5, train accuracy 0.921, test accuracy 0.924
.Epoch 6, train accuracy 0.935, test accuracy 0.931
.Epoch 7, train accuracy 0.947, test accuracy 0.938
.Epoch 8, train accuracy 0.957, test accuracy 0.945
.Epoch 9, train accuracy 0.965, test accuracy 0.952
.Epoch 10, train accuracy 0.967, test accuracy 0.958
.Epoch 11, train accuracy 0.972, test accuracy 0.968
.Epoch 12, train accuracy 0.978, test accuracy 0.967
.Epoch 13, train accuracy 0.978, test accuracy 0.968
.Epoch 14, train accuracy 0.982, test accuracy 0.969
.Epoch 15, train accuracy 0.985, test accuracy 0.977
.Epoch 16, train accuracy 0.987, test accuracy 0.973
.Epoch 17, train accuracy 0.990, test accuracy 0.977
.Epoch 18, train accuracy 0.991, test accuracy 0.984
.Epoch 19, train accuracy 0.993, test accuracy 0.981
.Epoch 20, train accuracy 0.993, test accuracy 0.977
.Epoch 21, train accuracy 0.993, test accuracy 0.985
.Epoch 22, train accuracy 0.996, test accuracy 0.978
.Epoch 23, train accuracy 0.994, test accuracy 0.986
.Epoch 24, train accuracy 0.997, test accuracy 0.984
.Epoch 25, train accuracy 0.996, test accuracy 0.985
.Epoch 26, train accuracy 0.997, test accuracy 0.986
.Epoch 27, train accuracy 0.997, test accuracy 0.988
.Epoch 28, train accuracy 0.998, test accuracy 0.988
.Epoch 29, train accuracy 0.992, test accuracy 0.989
.Epoch 30, train accuracy 0.997, test accuracy 0.986
.Epoch 31, train accuracy 0.998, test accuracy 0.983
.Epoch 32, train accuracy 0.998, test accuracy 0.993
.Epoch 33, train accuracy 0.998, test accuracy 0.990
.Epoch 34, train accuracy 0.999, test accuracy 0.993
.Epoch 35, train accuracy 0.997, test accuracy 0.984
.Epoch 36, train accuracy 0.996, test accuracy 0.975
.Epoch 37, train accuracy 0.992, test accuracy 0.988
.Epoch 38, train accuracy 0.998, test accuracy 0.990
.Epoch 39, train accuracy 0.999, test accuracy 0.989
.Epoch 40, train accuracy 0.999, test accuracy 0.993
.Epoch 41, train accuracy 0.999, test accuracy 0.990
.Epoch 42, train accuracy 0.998, test accuracy 0.988
.Epoch 43, train accuracy 0.999, test accuracy 0.991
.Epoch 44, train accuracy 0.999, test accuracy 0.981
.Epoch 45, train accuracy 0.988, test accuracy 0.989
.Epoch 46, train accuracy 0.999, test accuracy 0.994
.Epoch 47, train accuracy 0.999, test accuracy 0.990
.Epoch 48, train accuracy 0.999, test accuracy 0.991
.Epoch 49, train accuracy 0.999, test accuracy 0.994